博客被人镜像了,如何『抢』回来
前两天,笔者吃饱了撑的没事干,打开 Umami 统计页面,结果发现有大量访客来访。奇怪的是,这些访客只看首页,不看别的,看了就走,而且还不知疲惫,没有Referer,IP也是固定的。
显然,这不是正常访客,而是站点恶意镜像(Malicious Site Mirroring)攻击。
 不成比例的访问数
不成比例的访问数1. 前言
站点镜像,顾名思义,就是直接把人家的站点给克隆下来。
而笔者碰到的,就可以进一步细分为基于反向代理的站点镜像,下面就简称『镜像代理』。比如说,攻击者把域名proxy.com解析到一台服务器上,并在服务器上运行反向代理,指向original.com。此时,用户访问proxy.com,看到的就是original.com的内容。
这样干的理由有很多,善意一些的,比如说访问无法直接访问/速度缓慢的站点(比如Google镜像站,软件源镜像站);而恶意一些的原因就很多了:
- 盗取文章内容
- 利用已经有一定SEO流量的站点,为域名引流,提高权重
- 作为 MITM,植入广告代码,用别人的资源来盈利
- 甚至,植入恶意代码,盗取登录信息等(比如,EvilProxy)
笔者之前也只是见过类似情况(某个做VPS测评的站长,发现自己的站被人镜像了。镜像还不打紧,攻击者还把页面上所有的AFF链接都换成了自己的,摆明就是想要借人家的资源来获利了),未曾料到这种事情会在自己的小博客上发生。
不过,兵来将挡水来土掩,既然见招,那咱们就拆招。
2. 事件调查
2.1 初步朔源
Umami里面能提供的资料并不是很多,因此转向查询Google Analytics,很快就能发现异常:本站并未提供繁体字内容,但GA统计却显示,出现了繁体字的标题:
 看来只是首页
看来只是首页显然,有某个东西正在爬取页面,然后用OpenCC之类的工具转换为繁体字,而且并未移除相关统计代码,导致对方的访问同样是记载了账上。为了确定是谁在爬取,接下来就是打开Cloudflare后台,进入域名页面,转到安全性——分析,果然可以看到,有一个IP正在高频请求站点根目录:
 下面两个是普通的路径扫描攻击,不管他
下面两个是普通的路径扫描攻击,不管他进一步分析请求详情,发现这个IP顶了一个GoogleBot的UA:

问题在于,GoogleBot作为一个相对来说还算好的爬虫,他最大的特点是:合法请求只能从Google自己的IP段发出,以及这个IP是可以查到谷歌自己的rDNS的。对于攻击者的IP来说,显然并非如此,不仅不是谷歌,反而还指向了一个卖网页托管的共享虚拟主机的商家:
# dig -x 66.249.xxx.xxx +short
crawl-66-249-xxx-xxx.googlebot.com.
# dig -x 68.x.x.x +short
xxxxx.a2hosting.com.
既然是网页托管主机,那就进一步坐实了这是个镜像代理。
看起来,这个代理(或者说,这个域名)还挺热门的,除了上面的大量访问之外,其访问的目录也很有意思:
 手机号部分打码
手机号部分打码hmjx是『号码吉凶』的意思,后面就是手机号了。至于为什么可以肯定这里是号码吉凶,这里先卖个关子,下面再聊。
2.2 应急处置
既然知道了对方只有这一个IP,那就先屏蔽一下这个IP。
转到安全规则页面,添加一条规则:
(ip.src eq 68.xx.xx.xx)为了避免误伤(也许有的)正常用户,处置动作就选择托管质询,然后点击保存。一切无误的话,很快就能看到有事件被出发,且CSR(通过验证码的比率)很低,甚至为0:
 截图后补的,因此末端数值下降
截图后补的,因此末端数值下降此时,对方就应该打不开页面了。
2.3 通知主机商
与此同时,既然知道了IP属于谁,当然还可以进一步通知IP所有者。
在这家主机商页面上找到滥用举报的邮箱,找了个大模型帮忙起草一份英文邮件,自己再想办法润色一下,核对无误之后,就给对方发过去了。不确定这么做有没有用,反正目前对方还没有回信。
 笔者的英语不算太好,还得想办法润色
笔者的英语不算太好,还得想办法润色2.4 深度朔源
当然了,事情哪有这么简单?一方面,肯定是想调戏一下攻击者的,另一方面,如果对方更换IP,那么自然可以绕过这个简单的屏蔽措施。所以,我们需要进一步的朔源。
这个过程其实没那么容易。前两天,定位到攻击者之后,一开始尝试在搜索引擎(包括Google和Bing)直接精确搜索繁体字标题,可能是因为这两天刚开始进行爬取,结果自然是一无所获。随后又尝试检索标志性用语(就是文末的那个『木头箱子脆脆』),同样也是没有找到。
另一方面,因为这个IP是共享虚拟主机,也就是说会有多个网站使用这个IP,在不知道对方使用什么域名的情况下,很难做到精确定位站点。
 直接访问只有这个
直接访问只有这个借助网络空间测绘平台去查询,倒是个好主意。笔者有FOFA账号,但因为同样的原因,FOFA上也没有匹配的记录,只能查到这个IP目前运行有什么网站:
 有不少网站托管在上面
有不少网站托管在上面几番尝试之后,还是没有结果,这件事就只能先搁置了。
不过,好在天无绝人之路。今天突然想起来一个好东西:Backlink(反向链接,也就是外链)。
做过SEO的朋友,应该对外链这个名词不陌生,简单来说,外链就是其他网站上面放置了你的网站的链接。一般认为,外链数量越多,说明其他网站越认可你的站点(不然也不会放上去),你这个站点/域名的价值也就越高,搜索引擎也更倾向于多给流量。当然,市面上也有很多查询外链的网站,方便做站的人去查询当前的外链数量,以便改进SEO。
我们目前不是关注SEO,而是试图找到引用了笔者站点的且不同域名的那个站。这个做法,老实说,其实有点瞎猫碰见死耗子的成分,因为攻击者完全可以把链接全部替换掉,我们赌的就是攻击者没有把链接全部替换完,还留了一些地方,可以被搜索到,比如说,图片链接。此外,和上面的几个方法一样,也有可能因为爬取时间过短,未被检索站收录,而无法找到攻击者的站点。
有可能真的是走运吧,笔者找了个查外链的网站,输入了自己的域名,结果还真给找到了:
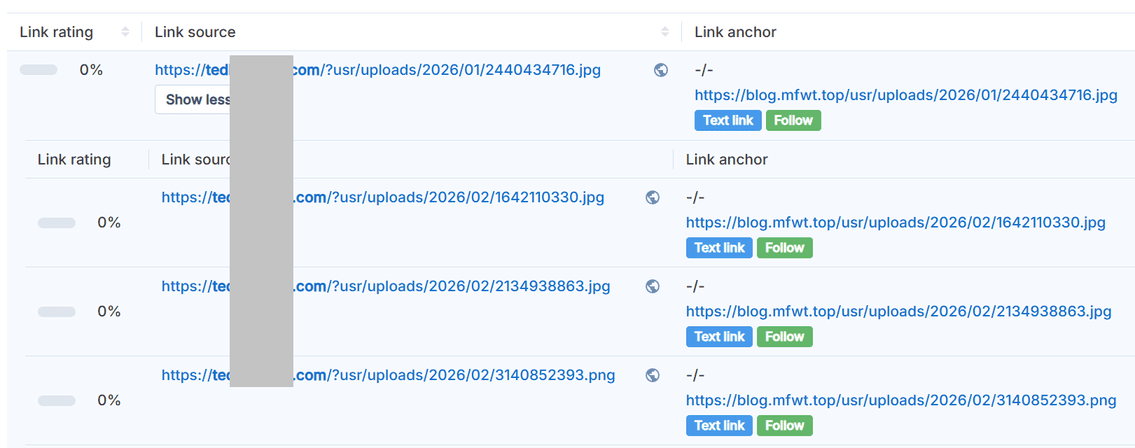
检查发现,这个域名指向的确实是上面提到的IP地址:
# ping ted*****.com
PING ted*****.com (68.xx.xx.xx) 56(84) bytes of data.
64 bytes from xxxx.a2hosting.com (68.xx.xx.xx): icmp_seq=1 ttl=57 time=10.9 ms
64 bytes from xxxx.a2hosting.com (68.xx.xx.xx): icmp_seq=2 ttl=57 time=10.9 ms
......直接访问这个域名,会弹出虚拟主机的默认证书:
 还是Let's Encrypt的
还是Let's Encrypt的去CF后台关掉拦截规则,继续访问此站点,一切就水落石出了:
 已经把他存档到网页时光机
已经把他存档到网页时光机正是这个域名所对应的网站,在镜像代理笔者的博客,并将内容转换为繁体字发布。而且显然,转换效果特别差,页面有乱码不说,甚至下面有把『香港』转换为『喷鼻港』的情况,笑死。
查看源代码可以发现,页面底部被攻击者插入了大量的广告和统计代码,这就坐实了之前的猜测,用别人的资源来盈利。
 谷歌广告代码
谷歌广告代码进一步查询域名发现,攻击者之前还镜像过别的站点,其中就包括一个在线工具站(而且同样出现了类似的繁体字转换错误)。联想到IP138之类的站点,除了正经工具之外,还有所谓的手机号码测吉凶功能,因此这个工具站也提供此类功能,并被镜像代理掉,恐怕也很合理。
 必应有收录
必应有收录2.4.1 为什么能找到外链
其实完全可以说,这个找外链的过程完完全全就是瞎猫碰见死耗子。
分析请求头可以发现,对方使用的是基于PHP的代理程序(毕竟是虚拟主机,不是完整的VPS)。笔者曾经玩过这类玩意,一般都是通过Curl发请求,然后再处理文本内容,最后echo出来,完成代理过程。
像这样的镜像代理站,显然是不可能暴露源站链接的,毕竟这和自投罗网没什么区别。所以在处理内容的那一步,一般都会通过正则替换之类的方式,把出现的明文源站域名都替换掉。也因为如此,网上教你的『添加<link rel="canonical">标签,标注权威页面』的方法,会直接失效,因为源站域名就在里头,直接换掉就行。
此外,一个正常的网站除了HTML和CSS/JS之外,还存在图片,而图片文件的大小,就不是纯文本能比的了。因此,除非要做戏做全套,否则为了节省流量,这些站点一般都会从被盗的源站加载图片,也就是俗称的盗链。
现在矛盾出现了:既不能直接出现源站链接,又需要加载源站的图片。开发这个代理程序的人想出来一个天才主意:在图片路径前加一个问号,再拼接到镜像站域名上,同时服务器配好伪静态。这样,图片路径就成为了查询参数,能被代理程序感知到,代理程序就可以返回HTTP 302响应,Location设置为源站域名,浏览器就自动跳到源站加载图片了。如果用户不打开DevTool,或者直接访问链接(绝大多数用户应该都不会),除了图片加载略慢之外,根本不会发现问题所在。
也正是因为这个302的存在,查外链的网站就可以感知到两个不同的域名,并把它收录下来,被我们查询到。
3. 提示与预防措施
既然我们知道了谁在镜像,为了预防这类事情再次发生,就可以上些科技了。
以下方法都是很粗糙的,但还算好用,如果你也想用,请注意检查与核对代码。
3.1 后端代码
整个爬取期间,对方没有更换IP,因此自然不能放过这个资源。
导航到源站的根目录下,新建antiMirroring.html,写入一些提示语。因为我们知道对方的代理程序会替换掉明文源站域名,而且把简体字变成繁体字;同时而且考虑到响应速度问题,显然也只能是简单替换,所以我们也以毒攻毒,来点简单的混淆手段,把提示语混淆掉,防止被转换:
<html>
<head>
<title>回家的路</title>
<style>.road {display: none;width: fit-content;margin: 5px auto;}</style>
</head>
<body>
<!-- 把提示内容用URL编码混淆一下 -->
<!-- 不过,大多数转换器不会编码ASCII字符,需注意 -->
<h3 class="road">%E5%B7%B2%E6%A3%80......</h3>
<h3 class="road">%E8%AF%B7%E5%88%B0.......</h3>
</body>
<script>
document.querySelectorAll('.road').forEach((e) => {
e.innerText = decodeURIComponent(e.innerText);
e.style.display = 'block';
});
</script>
</html>接着,打开index.php,在Typecho的加载代码之前,插入我们的防盗代码:
$ip = htmlspecialchars(getallheaders()['Cf-Connecting-Ip'],ENT_QUOTES,'utf-8');
if($ip == '68.xx.xx.xx') {
include __DIR__.'/antiMirroring.html';
die();
}
// 以下是原来的代码,省略这样,其他用户就正常访问,当这个镜像代理站来爬的时候,就只能看到我们的提示语:
 查看本站前端源代码,能找到上面的句子
查看本站前端源代码,能找到上面的句子3.2 前端代码
考虑到可能以后还有别的镜像代理站前来爬取,因此还可以在前端上也下点功夫,就能不依赖特定的IP地址了。
导航到主题的header.php,这个是公共引入的文件,在里面添加js代码,就可以被各个页面引用。我们的目的是判断当前页面域名是不是规定的主域名,又不能直接出现设定好的主域名,避免被换掉,因此也要混淆。这里的混淆方法就略微复杂些,把域名倒着写,然后编码为base64,判断的时候反过来操作就行:
// 这里的示例域名是 example.com
let a = window.atob("bW9jLmVscG1heGU=").split('').reverse().join('');
if(window.location.host !== a) {
window.stop()
window.location.href = `https://${a}/`;
}当然,你也可以根据自己的需求,调整混淆算法,但毕竟万变不离其宗,因此这里不再展开。
4. 写在最后
老实说,我想了半天,也没想明白攻击者为啥要针对这个名不见经传的小博客,就为了放广告?
其实笔者并不是说绝对不允许转载,正如下面所见,只需要保留出处,最好告知一下,那是一般情况下都没啥问题的。像这样直接整个站搬过去的,那就有点说不过去了。
同理,笔者其实也不太介意目前的内容被拿去训练大模型,甚至拿去给大模型做联网搜索的参考资料都没啥问题,但最好不要用大模型来造狗屎不通的屎,谢谢了:
 某SERP API供应商用LLM造的翔,引用了本站文章
某SERP API供应商用LLM造的翔,引用了本站文章(完)

很强大,学习了
能帮上忙就好,主要是这种事情确实很烦心,目前还在想有没有什么更为便捷准确的预警措施
我那边有总结了一下,欢迎指导
我也遇到过,记得是用了一行混淆js来跳转
混淆操作一定是要有的,不然他直接搜索到明文匹配的域名,就给你删掉了。我的建议是不要每个人都使用相同的混淆算法,都改一改,免得他直接把保护算法给删了(尤其是广撒网镜像的情况下)
之前也遇到过,我也是判断url然后再跳转的。
我去Google看了一下,似乎很多人都碰到了类似的情况
这家伙还在搬运啊,24年就开始了,还在搬……不过技术手段倒是稍微进步了一点 这是当年大家的一些反制措施:https://www.tjsky.net/tutorial/1026
只要有钱赚,估计他不会轻易停手的
博主是真大佬级别的,受教了。
谢谢
也可以做一个防盗链https://yfzhu.cn/posts/1014/参考这个哈
哈哈 手段如出一辙,当时我是发现发一个东西那边立马就镜像了,测试日志发现,有个bot,直接IP封禁就好了
估计就是专门发广告的了